




Your Company Spent Millions on AI. Do You Know What It Returned?
A leadership team approves a $2M AI initiative. Six months later, the model is live, the demo is slick, the press release is out. Someone asks the CFO what the return has been, and how it contributes to overall enterprise AI ROI.
Silence.
This often happens, not because the project failed, but because no one built a way to know if it succeeded. This is the most common AI story in enterprise right now, and it’s playing out on an enormous scale, raising deeper questions about why AI projects fail in enterprises.
MIT’s Project NANDA studied thousands of AI deployments and found that 95% of organizations report zero measurable ROI from their AI investments, despite the industry collectively pouring $30–40 billion into these initiatives. BCG found that only 4% of companies have achieved meaningful AI capabilities enterprise wide.
Technology isn’t a problem. The delivery model is.
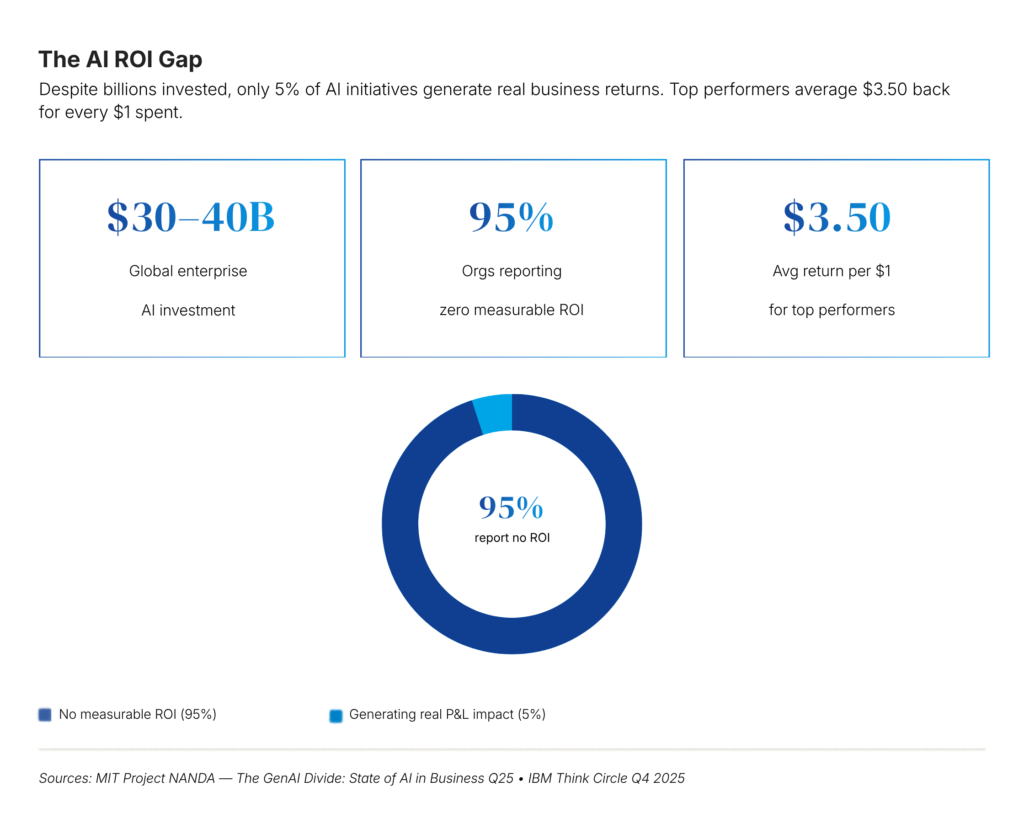
Enterprise AI ROI GAP
Accountability Is the Real Divider in Enterprise AI
It’s between companies that treat AI as a capability to deploy and companies that treat it as a bet to measure which is a distinction that ultimately shapes enterprise AI strategy ROI outcomes. The 5% who generate real returns aren’t working with better models. They’re working with better accountability.
They go in with a documented baseline. They define what “success” looks like before the first sprint starts. They instrument their systems to track value continuously instead of waiting for quarterly reviews when attention has already moved on to the next initiative. In doing so, they effectively building an AI ROI measurement framework into delivery itself.
“Every AI initiative is structured around a business outcome from day one — not retrofitted with justification after the fact.”
IBM’s research reinforces this point. Only 25% of AI initiatives deliver their expected ROI, and only 16% ever scale enterprise wide. The failure is not technical. It is structural, rooted in a delivery model that celebrates deployment but ignores results.
Three Questions To Answer Before Choosing A Model
Most AI-first data engineering Projects get scoped backwards. Teams start with the technology such as deciding to build an LLM powered chatbot and only later work toward a justification. ROI driven delivery reverses this approach and grounds decisions in how to measure AI ROI from the outset.
1. What is the baseline?
Concretely, what does this process cost today, in time, money, or error rate? If you can’t measure it now, you won’t be able to measure improvement later. PwC calls this the most common setup failure: organizations that skip baseline measurement are essentially committing to never knowing whether their investment worked.
2. What does good look like?
Not improved efficiency, because that is a direction and not a target. A meaningful definition would be reducing analyst time on report synthesis from four hours to forty five minutes per week. Specificity forces honesty. It also requires you to account for model error rates because real world AI accuracy is almost always lower than lab accuracy, which is a critical consideration when defining credible AI ROI metrics. Your ROI calculations must include the cost of wrong predictions, not just the value of correct ones.
3. What is the time-to-value window?
Stakeholder patience is finite. Top performers in MIT’s research moved from pilot to full implementation in about ninety days. They did not succeed because they rushed, but because they had a clear value hypothesis that created urgency and direction.
Not all AI bets deserve the same investment
One of the most consistent mistakes in enterprise AI is treating every use case with the same budget gravity. A copilot tool for your support team is not the same kind of bet as re-engineering your entire underwriting process.
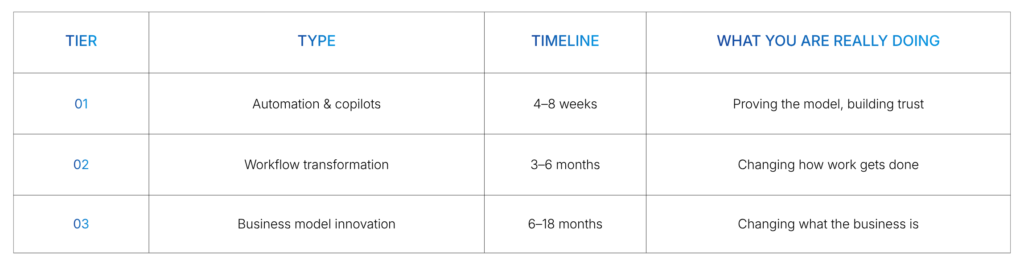
BCG’s research on AI leaders is instructive: top performers concentrate their bets on a small number of high-impact opportunities rather than running dozens of scattered pilots. Breadth feels safe. Concentration creates results.
The budget misallocation problem becomes clear here. MIT found that more than 50% of GenAI budgets go to sales and marketing because these are the most visible and easiest to justify use cases. However, the actual returns consistently come from back office automation, which is less glamorous but delivers far higher ROI.
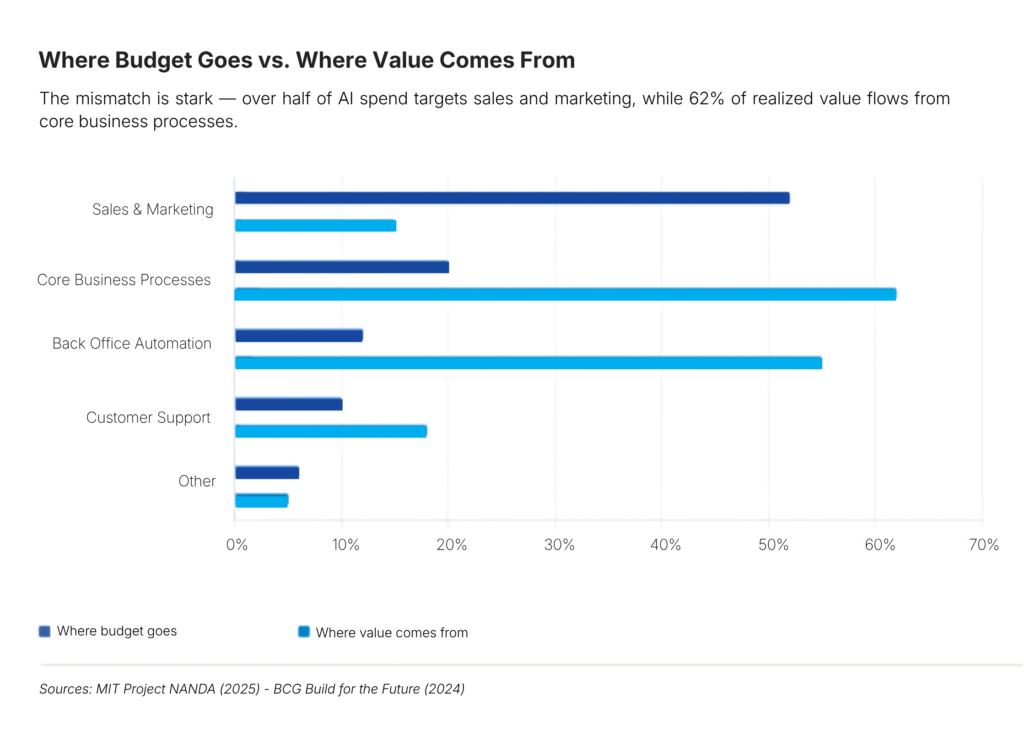
ROI isn’t an endpoint. It’s a signal you have to listen for continuously.
Here’s a failure mode that doesn’t get enough attention: the AI system that performs well at launch and quietly degrades over three months as the world around it changes, while no one is watching. PwC flags this explicitly. Machine learning models drift. Production data diverges from training data. User behavior shifts.
The organizations that sustain AI value treat measurement like infrastructure, not reporting. They track two layers simultaneously, embedding an ongoing AI ROI measurement framework into operations:
- Leading indicators (Trending ROI) : adoption rate, task completion time, escalation frequency, user engagement depth. These tell you early if something is working or breaking before the financial impact shows up and often surface hidden AI adoption challenges.
- Lagging indicators (Realized ROI) : cost per transaction, throughput per FTE, revenue impact, cycle time reduction. These confirm whether the system is delivering actual business value, not just activity.
One without the other is a distorted picture. Leading indicators alone create false confidence. Lagging indicators alone create late surprises. There’s also an attribution problem: if you don’t tag each workflow step as machine-generated, human-verified, or human-enhanced, you can’t accurately separate AI value from human judgment.
What you measure determines what you manage
Most organizations default to measuring what’s easy: tokens consumed, API calls, features shipped, models deployed. These are all outputs. None of them tell you whether the business is better off, which is why selecting the right AI ROI metrics becomes critical.
Direct business metrics
The ones your CFO cares about. Cost per transaction before and after. Throughput per FTE. Revenue per AI-assisted interaction. Resolution time reduction. IBM found that companies with strong returns average $3.50 back for every $1 invested, but only when they hold themselves accountable at this level.
Operational metrics
Model accuracy in production (not just in testing). User adoption rate. Fallback rate for agentic systems. Hallucination frequency. These are the early warning system for your business metrics and often expose underlying AI adoption challenges.
Strategic metrics
Market share delta attributable to AI differentiation. New revenue streams enabled. Organizational AI literacy. BCG’s 2025 study found that AI leaders set revenue growth targets 60% higher and cost reduction targets nearly 50% more ambitious than laggards , because they’ve built the measurement infrastructure to chase those targets with evidence.
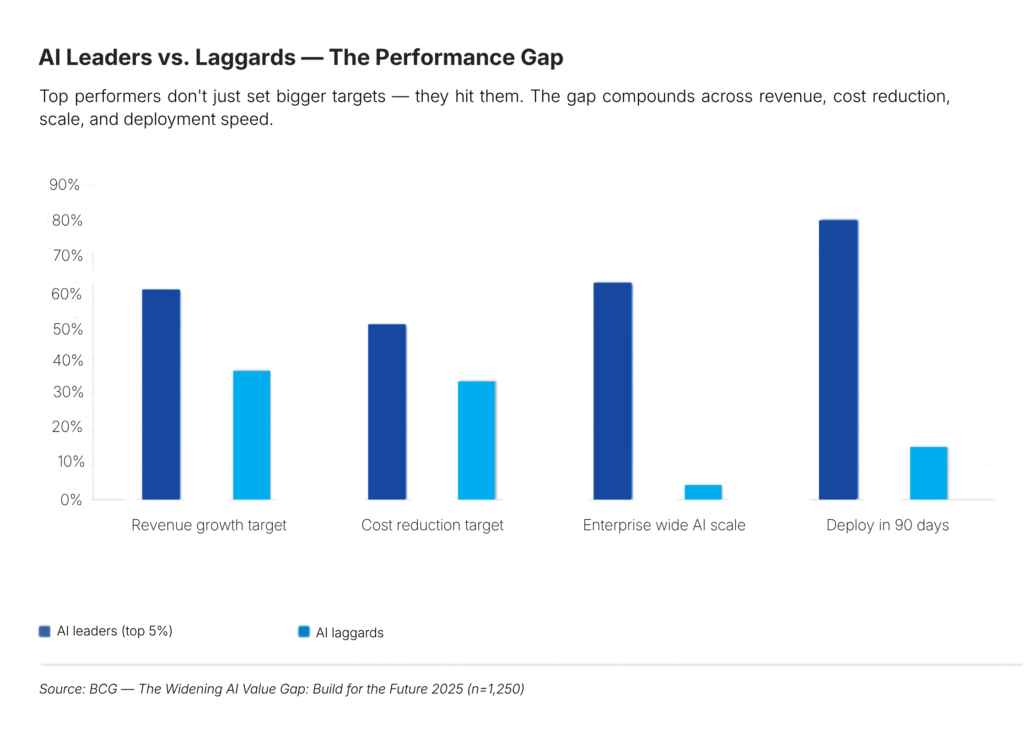
Common Enterprise Failure Modes That Erode AI ROI
Measuring activity instead of outcomes
Gartner found that 49% of CIOs cite proving AI’s business value as their single biggest challenge, and 85% of large enterprises don’t have the tools to track AI-native data engineering ROI properly, making how to measure AI ROI an unresolved capability gap. If your AI dashboard shows API calls and model uptime but not business outcomes, you’re not measuring ROI. You’re measuring effort.
Chasing visibility over value
The AI projects that get approved most easily are often the ones that look most impressive to leadership because it is customer-facing, branded, shareable. MIT’s data shows these front-office initiatives consistently underperform back-office automation in actual returns. Deploy where the value is, not where the applause is.
Ignoring adoption
A model with 95% accuracy used by 10% of the team returns less than a model with 85% accuracy used by 90% of the team. UC Berkeley’s SCET research found that team-level AI adoption consistently outperforms enterprise-wide rollouts because organic adoption drives deeper use and better feedback loops. This directly addresses core AI adoption challenges. Change management isn’t soft work. It’s a value multiplier.
Measuring ROI once
Leaders like PwC is direct about this: a single measurement point, typically a few months post-deployment, is almost meaningless. Systems drift, users evolve, workflows mature. The ROI picture at month one is almost never the ROI picture at month twelve.
Skipping the baseline
You cannot measure improvement from nothing. Before deployment, document exactly what the process costs today; in time, money, errors, and headcount. Without it, you’re not doing measurement. You’re doing storytelling.
AI ROI Failure Is an Organizational Problem, Not a Technology Problem
The gap isn’t technical anymore
The tools exist. The models exist. The infrastructure exists. What separates the 5% who generate real AI returns from the 95% who don’t is almost entirely organizational; how they scope initiatives, how they measure outcomes, and how they operationalize enterprise AI ROI across the business.
MIT’s research identified a “learning gap” as the root failure: most GenAI systems don’t retain feedback, don’t adapt to context, and don’t improve from real-world signals. But the same gap exists in the organizations themselves. Most enterprises launch, don’t learn, and move on to the next initiative carrying the same assumptions that caused the first one to fail quietly.
ROI-Driven Delivery Is Becoming a Core Leadership Competency
The companies that will define the AI landscape over the next decade aren’t the ones with the most models or the biggest compute budgets. They’re the ones that built a delivery culture where value has to be earned, measured, and proven, grounded in a clear enterprise AI strategy ROI mindset rather than assumption.
ROI-driven delivery isn’t a constraint. It’s the only way this actually works.