In the fast-paced business world, data is the lifeblood that fuels strategic decision-making and drives organizational success. However, even the most seasoned professionals can occasionally find themselves entangled in a web of data quality mishaps.
In the bustling headquarters of a thriving multinational corporation, resided Mr. X, a highly regarded senior manager renowned for his exceptional leadership skills and strategic acumen. With years of experience under his belt, he was trusted implicitly with critical decision-making and the company's most valuable asset- data. While working on a crucial report to understand the clinical trials data for a specific drug discovery, unknown to Mr. X, lurking within the depths of the data was a discrepancy that was missed during the initial analysis. A minor glitch in data extraction had caused a miscalculation, leading to an inflated projection of data.
As the blunder slowly emerged, the blame fell on Mr. X. The senior manager, once regarded as a beacon of expertise, found himself at the center of a storm, grappling with the harsh consequences of a data quality blunder. In the aftermath, the organization was forced to remove Mr. X from his position, reassess its data governance policies, implement stringent data quality measures, and invest in advanced data analytics tools to prevent such incidents from occurring in the future.
Despite the unfortunate outcome of Mr. X's experience, his story is not an isolated incident. In fact, data quality issues are pervasive in today's data-driven landscape, affecting organizations across industries and of all sizes. The implications of data quality mishaps can be far-reaching and devastating, leading to erroneous decisions, lost opportunities, damaged reputation, and significant financial losses. As businesses increasingly rely on data to gain a competitive edge and respond to dynamic market conditions, the need for accurate, reliable, and high-quality data becomes paramount.
In the bustling headquarters of a thriving multinational corporation, resided Mr. X, a highly regarded senior manager renowned for his exceptional leadership skills and strategic acumen. With years of experience under his belt, he was trusted implicitly with critical decision-making and the company's most valuable asset- data. While working on a crucial report to understand the clinical trials data for a specific drug discovery, unknown to Mr. X, lurking within the depths of the data was a discrepancy that was missed during the initial analysis. A minor glitch in data extraction had caused a miscalculation, leading to an inflated projection of data.
As the blunder slowly emerged, the blame fell on Mr. X. The senior manager, once regarded as a beacon of expertise, found himself at the center of a storm, grappling with the harsh consequences of a data quality blunder. In the aftermath, the organization was forced to remove Mr. X from his position, reassess its data governance policies, implement stringent data quality measures, and invest in advanced data analytics tools to prevent such incidents from occurring in the future.
Despite the unfortunate outcome of Mr. X's experience, his story is not an isolated incident. In fact, data quality issues are pervasive in today's data-driven landscape, affecting organizations across industries and of all sizes. The implications of data quality mishaps can be far-reaching and devastating, leading to erroneous decisions, lost opportunities, damaged reputation, and significant financial losses. As businesses increasingly rely on data to gain a competitive edge and respond to dynamic market conditions, the need for accurate, reliable, and high-quality data becomes paramount.
Data Quality can’t be an Afterthought
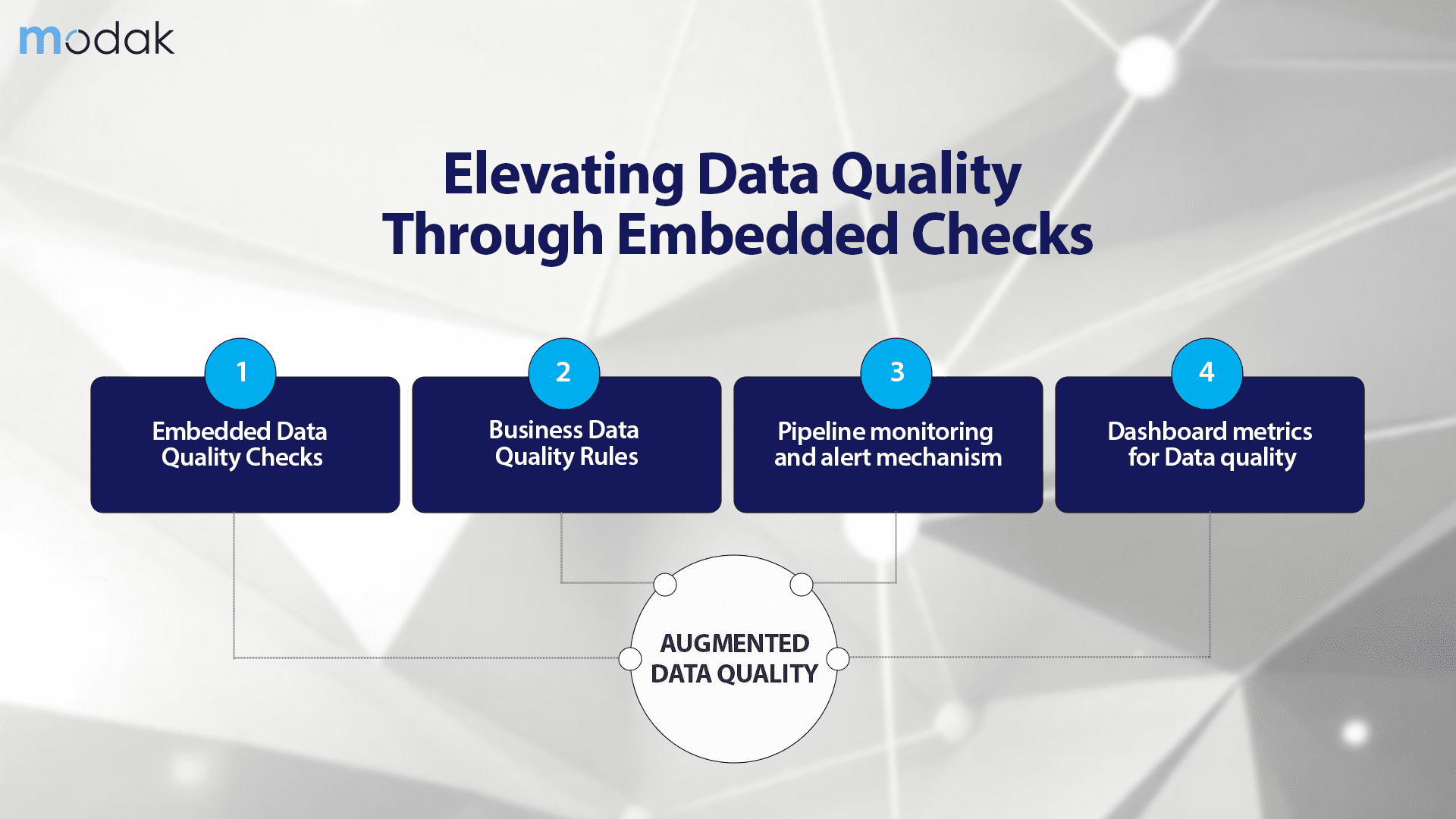
Organizations need to develop and implement data quality practices to detect and rectify all data quality issues as early as possible to not treat data quality as an afterthought. Organizations can enable this with tools that can incorporate and embed data quality rules in data pipelines, facilitating the flow of data through an organization's systems, to ensure consistent high-quality data delivery to data consumers. To implement robust data quality practices, organizations need a tool that provides capabilities such as embedded data quality rules, threshold setting, customized business-specific data quality (DQ) checks, ensure data governance and data quality alerts.
Embedded Data Quality Rules into Data Pipelines
To enable data pipelines to deliver high-quality data for consumption, it is essential to embed data quality rules directly within the pipelines. These rules can include industry-standard checks, such as verifying non-null values, validating date formats, or ensuring data falls within specific ranges. Additionally, organization-specific data quality rules, unique to each business or domain, should be added to the pipelines.
Business-specific Rules and Thresholds
Business rules are specific criteria or conditions set by the organization to define what constitutes good data quality. A good data quality solution empowers the users to customize the business data quality checks. These rules act as guidelines for data validation, ensuring that data adheres to specified business standards. Thresholds, on the other hand, represent the acceptable limits or ranges within which data must fall to be considered valid. If data fails to meet these predefined thresholds, alerts are triggered to notify relevant stakeholders of potential data quality issues.
Implementing Alert Mechanisms
Data pipelines can be equipped with alert mechanisms to promptly notify stakeholders when data quality rules are not met. Depending on the severity of the data quality issue, different levels of alerts can be configured. For instance, a hard pause can be set to halt the pipeline's operation until the issue is resolved, or a soft pause can be utilized, allowing the data to continue flowing while triggering an alert for investigation.
PII and Governance Process
Personally Identifiable Information (PII) is sensitive data that can directly or indirectly identify an individual, such as names, addresses, social security numbers, etc. Good data quality and governance processes involve establishing policies, procedures, and controls to manage and protect PII and other critical data assets. A robust governance process ensures data is handled ethically, securely, and in compliance with relevant regulations, while also addressing data quality concerns.
Schema Change/Drift and AI-Based Rules
Schema changes or drifting occur when there are alterations to the structure or format of the data. In data quality, it is crucial to monitor schema changes to detect any deviations that might affect data consistency and accuracy. AI-based and ML-driven data quality checks are employed to automate data quality checks, identify patterns, and predict potential issues.
Conclusion
The journey towards impeccable data quality is an ongoing one. Organizations must continuously adapt their approaches to keep up with the evolving data landscape and the emerging technologies that shape it. Organizations should prioritize robust data quality practices. Modern data quality tools, with the ability to incorporate data quality checks, alert mechanisms, industry and organization-specific data quality rules, contribute to ensuring enhanced data quality. As a result, organizations can mitigate the negative impacts of poor data quality, drive better decision-making, enhance customer experiences, and ultimately achieve their data-driven goals. Leveraging data pipelines ensures that poor-quality data does not infiltrate the organization's data ecosystem, safeguarding the integrity and reliability of valuable data assets.
About Modak
Modak is a solutions company dedicated to empowering enterprises in effectively managing and harnessing their data landscape. They offer a technology, cloud, and vendor-agnostic approach to customer datafication initiatives. Leveraging machine learning (ML) techniques, Modak revolutionizes the way both structured and unstructured data are processed, utilized, and shared.
Modak has led multiple customers in reducing their time to value by 5x through Modak’s unique combination of data accelerators, deep data engineering expertise, and delivery methodology to enable multi-year digital transformation. To learn more visit or follow us on LinkedIn and Twitter.
Author:

Aditya Vadlamani
Product Manager, Modak



