
Devesh Salvi
Product Analyst at Modak
What is a Data Fabric?
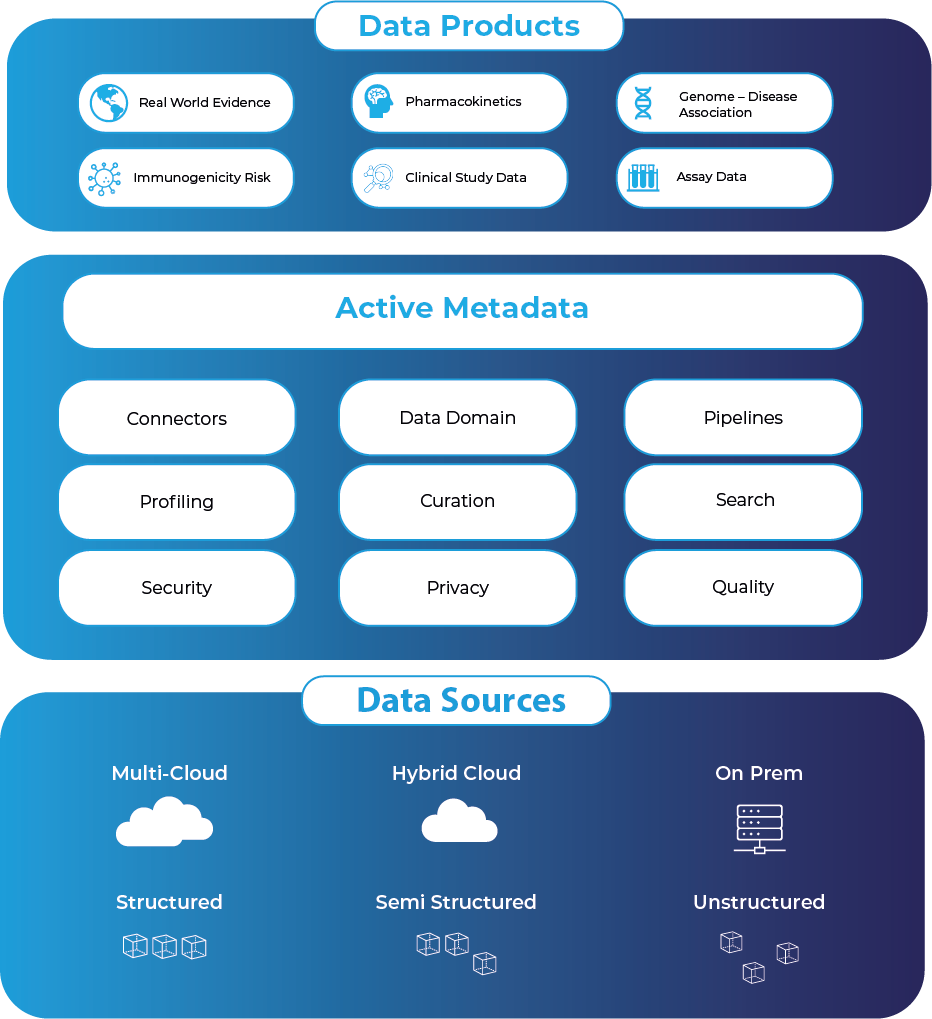
A Data Fabric needs to be seen from a data management design viewpoint, not from an implementation perspective. No single solution can provide a comprehensive one-stop-shop to enable a Data Fabric. Instead, multiple providers and consumers of data need to be brought together focused on three core tenets for a Data Fabric: agility, integration, and automation. These are supported by using an active metadata repository to capture the source technical and business metadata and visualized through semantic knowledge graphs. A Data Fabric provides data engineers and subject matter experts with the foundations to curate and deliver data domain products.
The main objective of a Data Fabric is to provide a “net” that is cast to stitch together multiple heterogeneous data sources and types, through automated data pipelines that proliferate an active metadata repository.
The main objective of a Data Fabric is to provide a “net” that is cast to stitch together multiple heterogeneous data sources and types, through automated data pipelines that proliferate an active metadata repository.
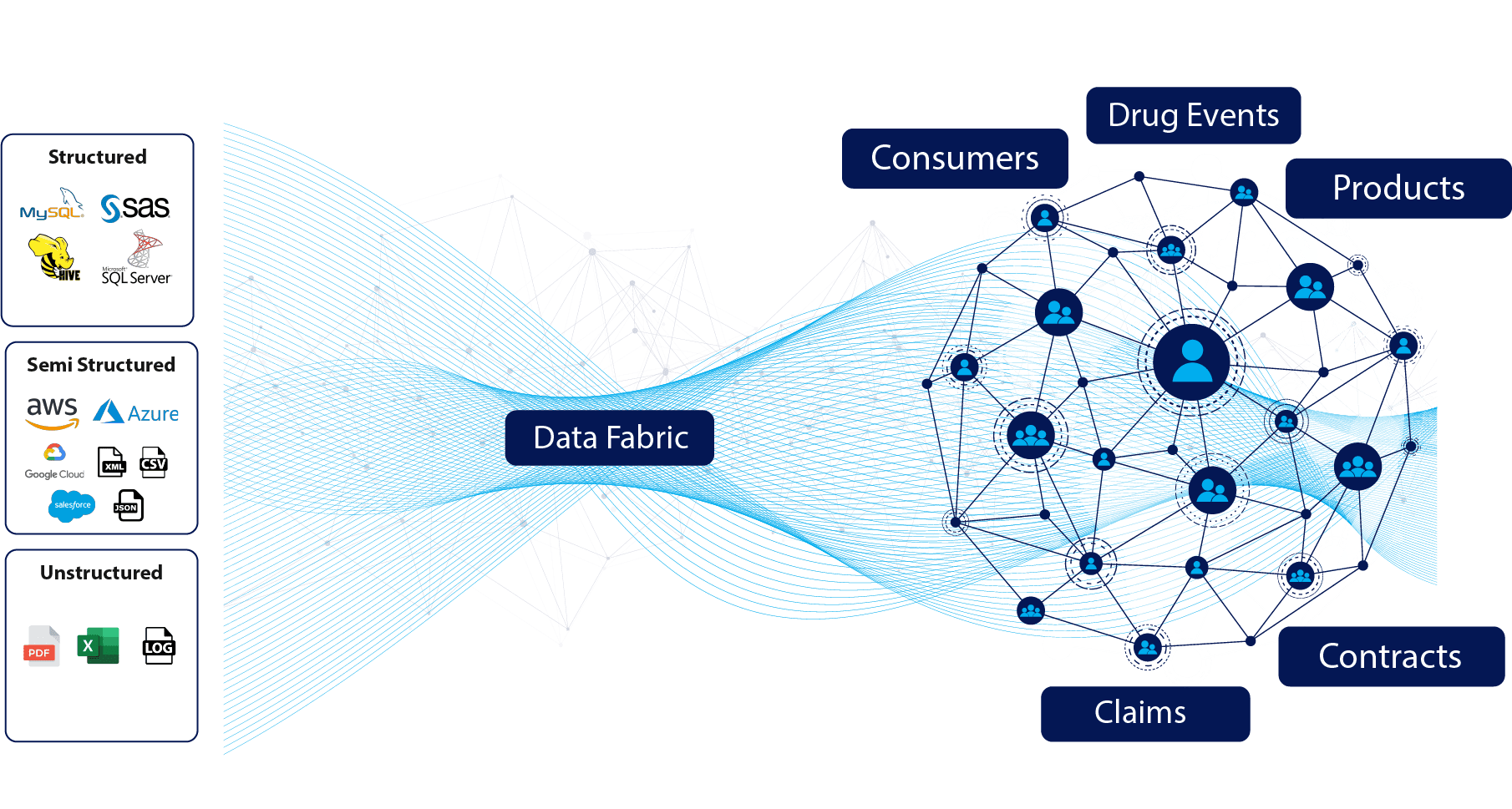
This allows for logical groupings (without moving the data) to create virtual data domains where augmentation techniques to apply tags (for example classify PHI data) or ML algorithms can be applied to automate the data quality and cataloging of data sets.
As such, a data fabric design is a collection of data services that deliver agile and consistent data integration capabilities across a variety of endpoints throughout hybrid and multi-cloud environments. Further, a Data Fabric adds a layer of abstraction, data can remain distributed with no movement of the physical data aside from crawling and profiling to create a logical map of the data landscape. This removes the need to replicate data for no outcome-driven reason.
Many organizations know that point-to-point integration patterns scale very poorly when faced with too many integrations. What starts out as one to few integrations, quickly morph to become a spaghetti of integration points. A good data fabric design aims to liberate this nightmare scenario with an active metadata catalog to repurpose existing data pipelines. Furthermore, enhancing the productivity of scarce Data Engineers by shifting away from manual, time-consuming, and error-prone ETL tools and toward low-code, UI-driven data pipeline creation saves time and money.
In summary, a Data Fabric can provide data architects and engineers with a design pattern where the focus is on the communication and collaboration with business users on the high-value use cases and less on the data infrastructure.
As such, a data fabric design is a collection of data services that deliver agile and consistent data integration capabilities across a variety of endpoints throughout hybrid and multi-cloud environments. Further, a Data Fabric adds a layer of abstraction, data can remain distributed with no movement of the physical data aside from crawling and profiling to create a logical map of the data landscape. This removes the need to replicate data for no outcome-driven reason.
Many organizations know that point-to-point integration patterns scale very poorly when faced with too many integrations. What starts out as one to few integrations, quickly morph to become a spaghetti of integration points. A good data fabric design aims to liberate this nightmare scenario with an active metadata catalog to repurpose existing data pipelines. Furthermore, enhancing the productivity of scarce Data Engineers by shifting away from manual, time-consuming, and error-prone ETL tools and toward low-code, UI-driven data pipeline creation saves time and money.
In summary, a Data Fabric can provide data architects and engineers with a design pattern where the focus is on the communication and collaboration with business users on the high-value use cases and less on the data infrastructure.
What is a Data Mesh?
The term Data Mesh was coined by Thoughtworks to address moving from monolithic data platforms to distributed data management. Data mesh aims to connect the two planes of operational and analytical data sets and deliver business-owned data products with a lifecycle (just as software) and consumed through APIs.
Consequently, a Data Mesh can be thought of as a consulting-driven data implementation paradigm that requires customers to balance the decentralized vs. centralized data domain creation, orchestration, governance and management pendulum.
The development of domain-specific Data Products follows the principles that they are discoverable via a self-service data marketplace, trustworthy as the business has validated and interoperable with other data domains and data sets.
A data domain product can be regarded as "dossiers" of institutionalized business knowledge that have been collaboratively curated and made available to a wide range of users. They complement currently limited and focused data marts that give information on specialized or targeted use cases and are based on structured (relational) data sets. Domain-driven Data Products, on the other hand, will have a broader and richer mix of structured and unstructured data to suit a variety of use cases, including fueling AI model design and development to answer the questions of tomorrow.
Consequently, a Data Mesh can be thought of as a consulting-driven data implementation paradigm that requires customers to balance the decentralized vs. centralized data domain creation, orchestration, governance and management pendulum.
The development of domain-specific Data Products follows the principles that they are discoverable via a self-service data marketplace, trustworthy as the business has validated and interoperable with other data domains and data sets.
A data domain product can be regarded as "dossiers" of institutionalized business knowledge that have been collaboratively curated and made available to a wide range of users. They complement currently limited and focused data marts that give information on specialized or targeted use cases and are based on structured (relational) data sets. Domain-driven Data Products, on the other hand, will have a broader and richer mix of structured and unstructured data to suit a variety of use cases, including fueling AI model design and development to answer the questions of tomorrow.
Devesh Salvi
Product Analyst at Modak




3 comments
Baz
04/08/2022 at 2:31 pm
Great article
Rima Chakraborty
04/08/2022 at 3:10 pm
Great Blog
Divya
04/11/2022 at 9:03 am
Nice