
Rajesh Vassey
Technical Program Manager, Modak
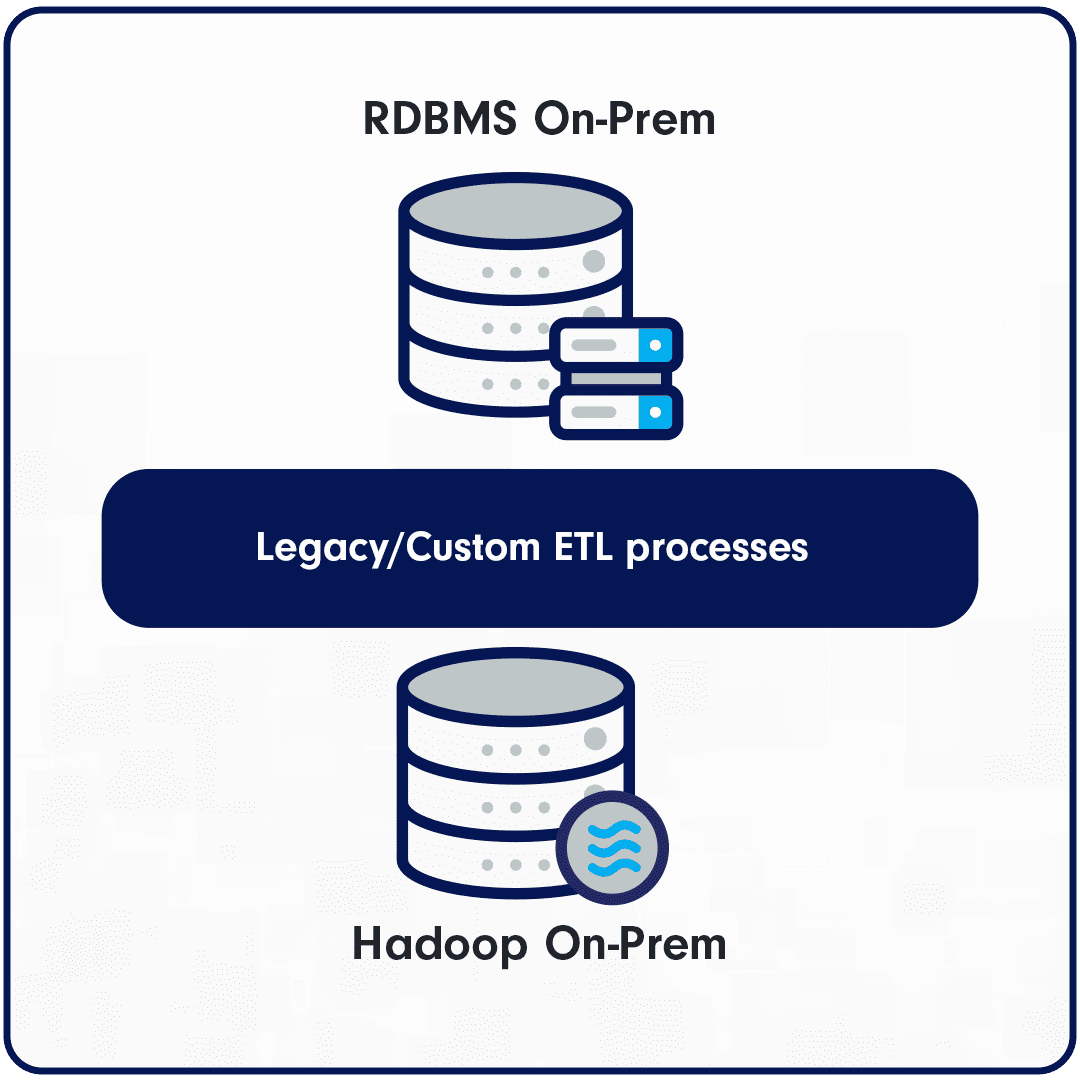
The critical data assets, often referred to as the ‘crown jewels’ for healthcare insurance companies are members and claims data. Historically, the Healthcare insurance company had built on-prem data lakes populated by transactional systems and external data providers to provide a single repository for analytical consumption. The software tools and data storage infrastructure were assembled on legacy ETL tools, and custom programs and hosted on Hadoop. Over time the complexity, lack of scalability, and investment required to maintain and support such an on-prem infrastructure became inflexible and cost-prohibitive. The challenge was to consider the options of how to modernize the software tools and migrate to the cloud and thereby move away from the current processes and dependency on Hadoop.
The data volumes and business integrity checks are significant, with approximately 10+ billion records to be migrated, legacy tools taking over 25 hours to process, and frequently failing and requiring a dedicated team of contractors to manage and support.
The data volumes and business integrity checks are significant, with approximately 10+ billion records to be migrated, legacy tools taking over 25 hours to process, and frequently failing and requiring a dedicated team of contractors to manage and support.
The design and development team set out the following objectives:
- Support the client’s multi-cloud strategy to securely operate across multi-cloud providers
- Ensure interoperability of data across on-prem and cloud provider systems
- Meet and improve on current business and IT service level agreements
- Ensure data compliance and regulatory needs are not compromised
- Provide a cloud data platform to fuel analytics and innovation
After evaluating incumbents, third-party software, and cloud provider tools the team selected Modak Nabu™, an integrated data engineering platform that accelerates the ingestion, profiling, and migration of data to any cloud provider. The Modak Nabu™ software provides data spiders to crawl, index, and profile large data sets, and automates the creation of data pipelines and Smart BOTs to orchestrate the data movement workflows from the on-prem enterprise source systems to the MS Azure Cloud ADLS2 platform.
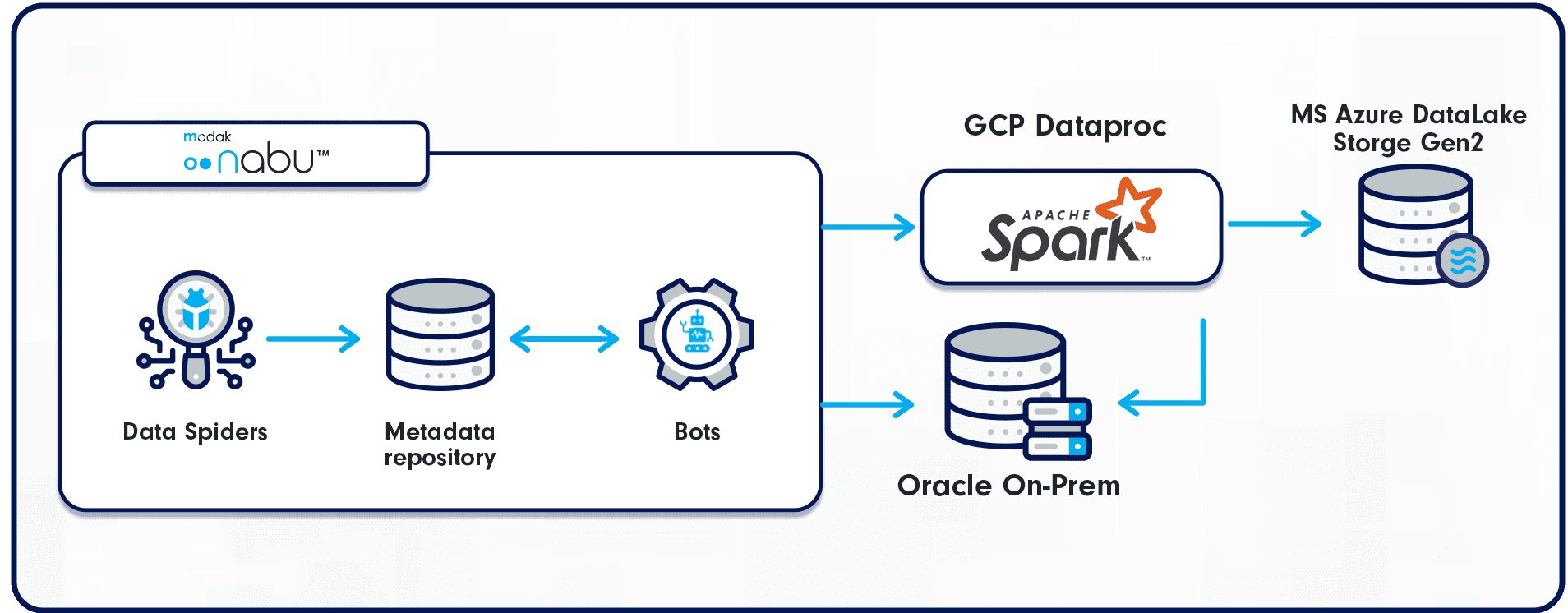
Due to the clients’ Cloud 3.0 multi-cloud strategy, and leveraging existing investment, Google’s DataProc Engine (Spark) was used as the compute processing engine to enable the migration and provide resiliency and performance.
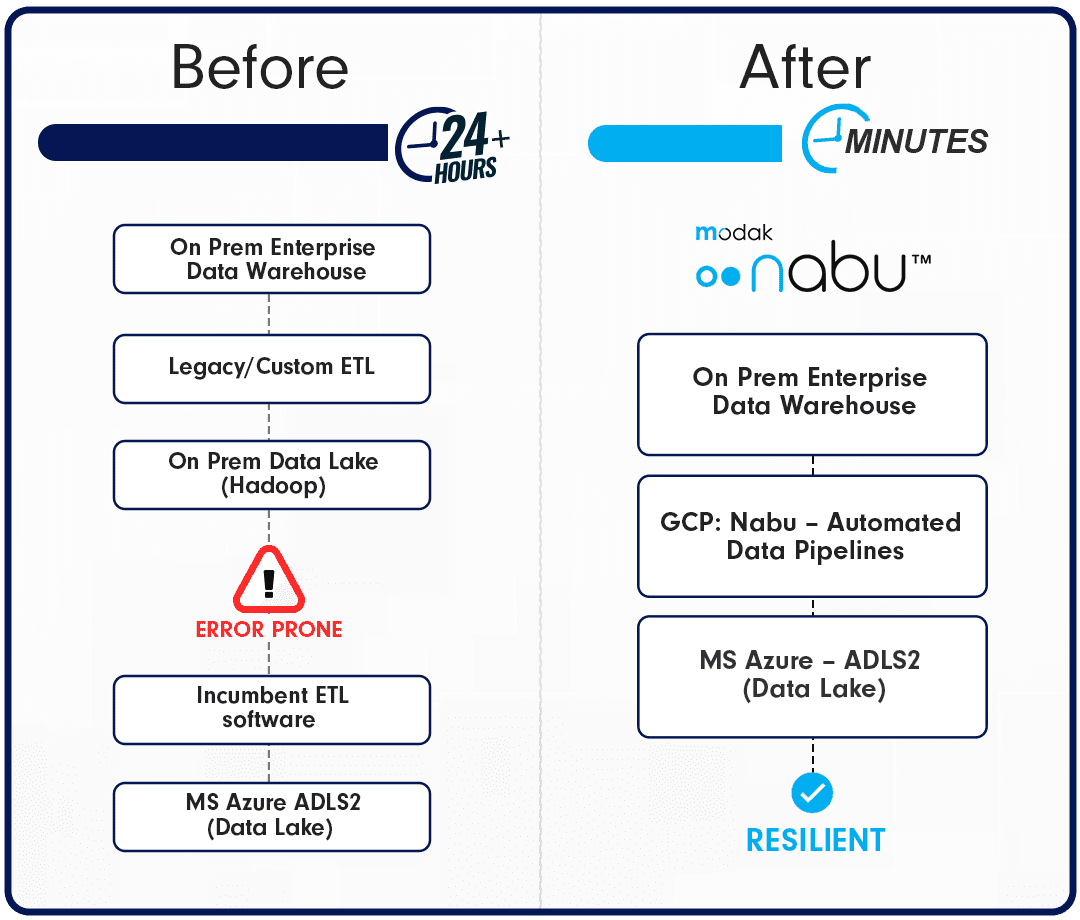
The outcomes and impact of the implementation of Modak Nabu™ are summarized as follows:
- Reduced cost and improved service due to the dependency on on-prem Hadoop removed
- Average data processing time improved by 85% from hours to minutes
- Eliminated the dependency on legacy ELT/ETL tools
- Less stress on source systems through the usage of parallel workloads implemented with Modak Nabu™
- Alignment with the clients’ hybrid cloud and multi-cloud strategy
- Availability and refresh of data into the MS Azure Data Lake within minutes for analysis
- Implementation of automated data pipelines, with robust message-driven fabric and real-time monitoring to meet SLA.
- An active metadata repository enabling the automation of data pipelines and BOTs to orchestrate data migration.
- Automatic identification of source data schemas enabling data pipelines, eliminating manual intervention and downtime.
Rajesh Vassey
Technical Program Manager, Modak



