The evolution of Artificial Intelligence (AI) and Large Language Models (LLMs) has taken the world by a storm since its inception. The ever-evolving landscape of Artificial Intelligence has continually pushed the boundaries of what's achievable. Evidently, the coming decades will witness unexpected advances in the limitless possibilities of AI.
At present, Large Language Models (LLMs) have emerged as a transformative force, revolutionizing how we interact with machines. These models, such as OpenAI’s ChatGPT, BingChat, Google’s Bard, among several others, possess unprecedented efficiency and personalization capabilities.
What are Large Language Models (LLMs)?
LLMs demonstrate an exceptional understanding of general, public knowledge. They can answer a wide array of questions, engage in conversations, and even generate creative content like poetry or code. However, their power lies in their ability to generate text based on patterns they've learned from vast amounts of data.
Open-source LLM (Large Language Model) models, while often robust and versatile, might not adequately align with the intricate demands of enterprise use cases. These limitations stem from the absence of training on contextual datasets unique to businesses. These models, typically trained on publicly available information from diverse sources on the internet, lack exposure to the nuanced and proprietary data that define enterprise settings.
LLMs encounter substantial challenges in grasping the specific context of enterprise-related inquiries. Despite this broad training, these models like GPT-4, lack access to proprietary enterprise data sources or knowledge bases.
Consequently, when posed with enterprise-specific questions, LLMs often exhibit two primary types of responses: hallucinations and factual but contextually irrelevant answers.
Hallucinations:
Hallucinations characterize instances where LLMs generate fictional yet seemingly realistic information. These hallucinations present a challenge in distinguishing between factual data and imaginative content. For instance, an LLM hallucination might occur when asking about the future stock prices of a company based on current trends. While the LLM may produce a convincing response based on existing data, it's purely speculative and doesn't guarantee accuracy in predicting future stock values.
Irrelevant Answers:
Factual but out-of-context responses occur when an LLM lacks domain-specific information to provide an accurate answer. Instead, it generates a truthful yet generic response that lacks relevance to the context of the query. For instance, a query is about the cost of "Apple" in the context of technology. If the LLM model lacks specific domain knowledge or access to current market prices, it might provide factual yet unrelated data, such as the prices of fruits or historical information about apple cultivation, which, while accurate, is irrelevant in the intended technological context.
Apart from the above-mentioned challenges LLMs face other limitations as discussed below:
Challenges of Enhancing LLMs with Private Data
While the concept of enhancing LLMs with private data is intriguing, its execution involves various challenges and considerations:
- Data Privacy and Security: One of the primary concerns when integrating private data with LLMs is data privacy and security. Private data may include confidential customer information, intellectual property, or sensitive business strategies. Organizations must implement robust data protection measures to ensure that proprietary data remains secure and is not exposed to unauthorized parties.
- Data Quality and Bias: The quality of the private data used to enhance LLMs is paramount. Poor-quality data can lead to inaccurate results, while biased data can perpetuate harmful stereotypes or generate biased responses. It's crucial to address data quality and bias mitigation during the data integration process.
- Retraining and Regular Updates: Private data integration is not a one-time process. Organizations should plan for periodic retraining and updates to keep LLMs aligned with evolving business requirements and changes in the private data landscape.
- User Access Control: Implement strict access control mechanisms to restrict who can interact with LLMs enhanced with private data. This minimizes the risk of unauthorized users accessing sensitive information.
Despite all the challenges, enterprises have found themselves tapping into the potential of LLM with private data. However, this paradigm has raised concerns regarding optimizing LLMs with private data, data safety, and ethical practices. In this blog, we elucidate the important aspects of enhancing LLMs with private data and uncover the implications for your enterprise.
Benefits of Enhancing LLMs with Private Data
The integration of private data into LLMs offers numerous advantages. By doing so, we empower these models to become even more tailored to specific tasks and industries.
Some of the key benefits of enhancing LLMs with private data are:
- Personalization: Integrating private data enriches LLMs, enabling them to provide more personalized and targeted insights specific to individual users or organizations.
- Confidentiality: The inclusion of private data ensures that sensitive information remains secure within the LLM, safeguarding proprietary details from external exposure.
- Improved Accuracy: Incorporating private data refines the accuracy of LLM-generated insights, aligning them more closely with the nuanced requirements of specific industries or contexts.
- Tailored Precision: Private data empowers LLMs to offer more nuanced and precise recommendations or responses tailored to the intricacies of an organization's needs.
- Enhanced Security Measures: The utilization of private data within LLMs ensures the implementation of heightened security protocols, fortifying the protection of sensitive information.
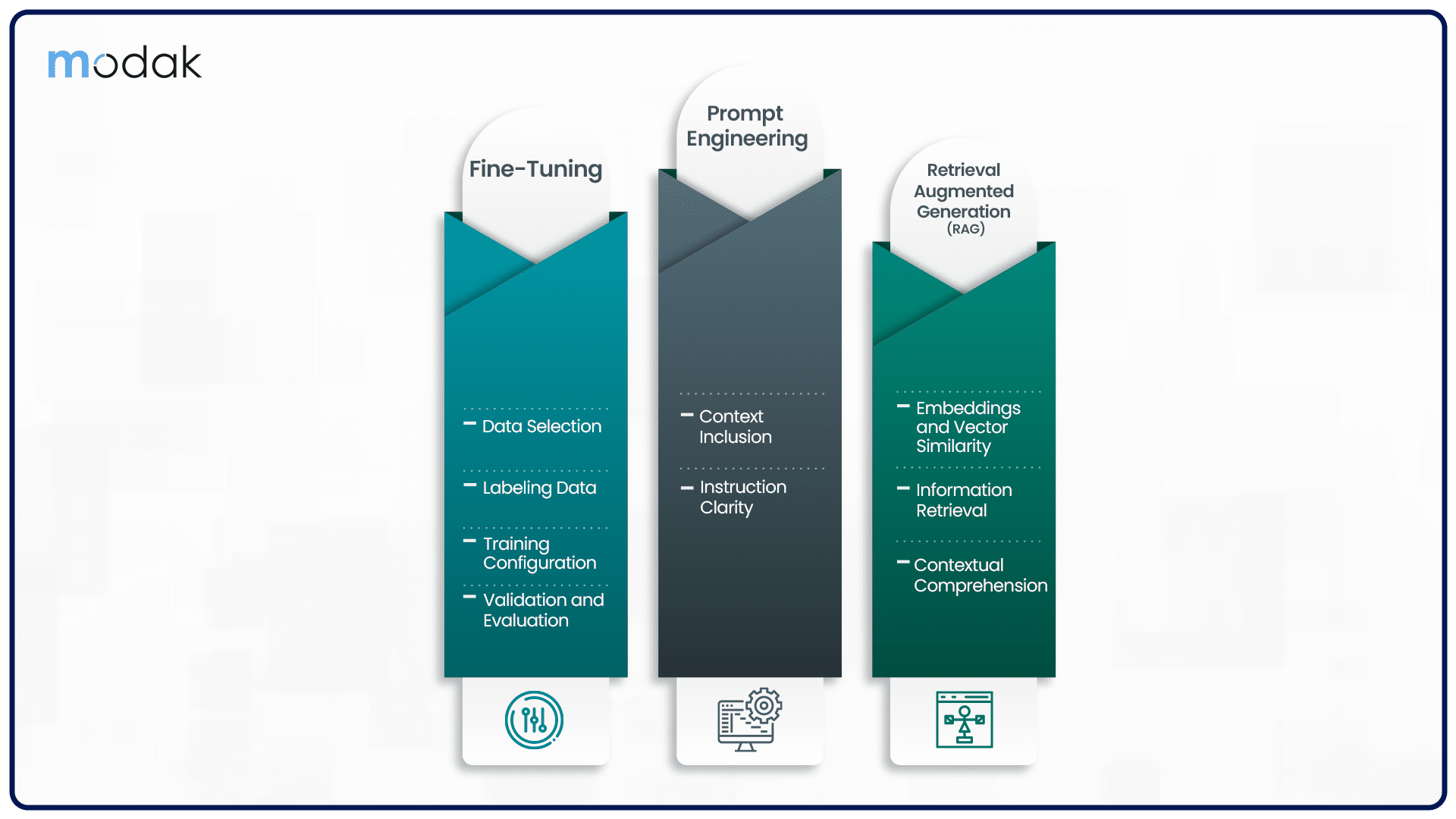
Methods for Enhancing LLMs with Private Data
Now, let's explore the methods in more detail:
Fine-Tuning
Fine-tuning involves adapting a pre-trained LLM to specific tasks or domains using private data. Here's a more in-depth look at fine-tuning:
- Data Selection: Carefully select the private data that aligns with the intended task. This may involve using historical customer interactions, internal documents, or proprietary knowledge.
- Labeling Data: Create labeled datasets to train the model. Assign labels or categories to private data to guide the model in generating appropriate responses.
- Training Configuration: Configure the fine-tuning process, including the number of epochs, learning rate, and batch size, to achieve optimal results.
- Validation and Evaluation: Continuously validate and evaluate the model's performance using validation datasets. Fine-tuning is an iterative process that requires constant monitoring.
Prompt Engineering
Prompt engineering is a technique where tailored prompts are crafted to provide context or instructions to LLMs. This method is essential for guiding LLMs when working with private data.
- Context Inclusion: When crafting prompts, include relevant context from private data sources to inform the LLM about the task or the domain-specific information.
- Instruction Clarity: Ensure that prompts provide clear and specific instructions, so LLMs can generate meaningful responses that incorporate private data insights.
Retrieval Augmented Generation (RAG)
- Embeddings and Vector Similarity: Create embeddings from private data sources, such as documents or internal knowledge bases. These embeddings help identify relevant information for inclusion in LLM responses.
- Information Retrieval: Use information retrieval methods to match user prompts with the most relevant content from private data sources. This content can then be included in LLM responses.
- Contextual Comprehension: RAG ensures that LLMs have a deep understanding of the context, leveraging private data to provide more accurate and context-aware answers.
Retrieval Augmented Generation (RAG) techniques allow LLMs to incorporate external information from private sources into their responses. This approach enhances the model's understanding of the topic and ensures the utilization of private data.
Conclusion
About Modak
Modak is a solutions company dedicated to empowering enterprises in effectively managing and harnessing their data landscape. They offer a technology, cloud, and vendor-agnostic approach to customer datafication initiatives. Leveraging machine learning (ML) techniques, Modak revolutionizes the way both structured and unstructured data are processed, utilized, and shared.
Modak has led multiple customers in reducing their time to value by 5x through Modak’s unique combination of data accelerators, deep data engineering expertise, and delivery methodology to enable multi-year digital transformation. To learn more visit or follow us on LinkedIn and Twitter.




